
Увод
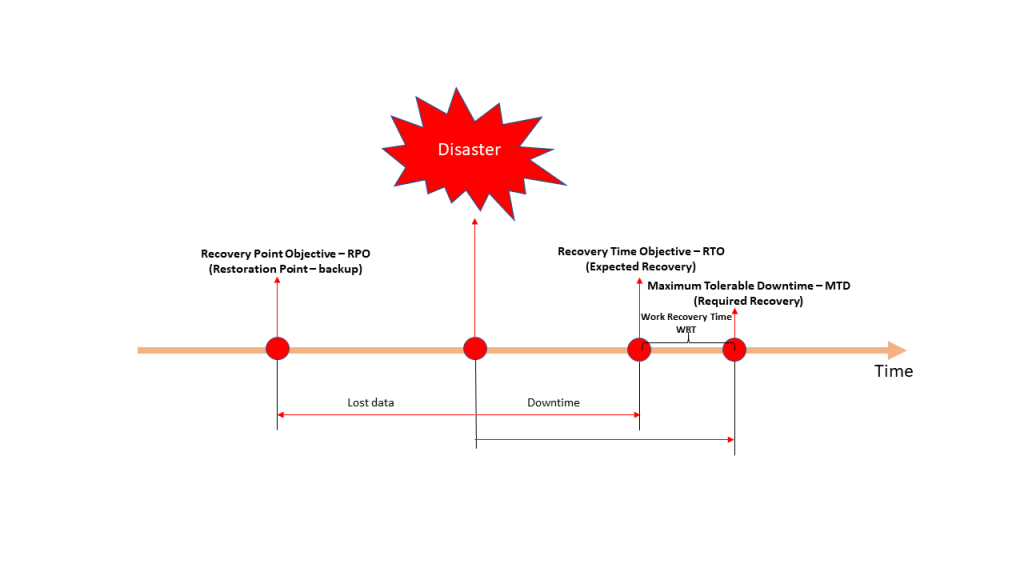
У случају катастрофе, свака организација мора имати сет стратегија опоравка и решења унапред припремљених за заштиту и враћање пословно-критичних апликација. Према анализи пословног утицаја (BIA) RPO, RTO и MTD су дефинисани.
RPO вредност је колико је података, мерено у времену, дозвољено изгубити. RPO се дефинише на основу количине података који се могу изгубити у временском периоду пре значајног оштећења пословања. РПО се користи за одређивање учесталости креирања резервних копија података.
RTO вредност је колико је потребно да се остваре циљеви рестаурације, пре него што достигне максимално толерисано време недоступности (MTD).
MTD вредност је колико је потребно да се обнови, од катастрофе до потпуно оперативног стања. MTD се дефинише на основу количине времена колико апликације и пословни процеси могу бити недоступни, а да се не наносе штета пословању. MTD се често превиди, из ИТ перспективе, јер WRT процедура захтева време да се провери да ли су сви системи синхронизовани, а подаци проверени и тестирани да би се уверили да су у правом низу.
Опоравак од катастрофе
Опоравак од катастрофе представља стратегије и решења, која су традиционално била начин да се реагују на све врсте прекида рада (природне, хардверске и софтверске грешке и грешке које је направио човек). Он представља скуп процедура за повратак приступа и функционалности ИТ инфраструктуре у пуно оперативно стање после катастрофалног прекида. То значи да је опоравак катастрофе мануелни задатак за спасавање података на локацији за опоравак коришћењем реплицираних података. За аутоматизацију опоравка користе се алати као што је VMware Site Recovery Manager (SRM).
Избегавање катастрофа
Питање је, да ли се катастрофа моће избећи? Постоји ли начин да будемо проактивни и обезбедимо приступ подацима чак и ако се деси катастрофа? Одговор је да. Уместо опорављања података, предвиђамо избегавање катастрофа и припремимо се за катастрофу пре него што се догоди. Избегавање катастрофа омогућава пословно критичним апликацијама, и виртуелним машинама на којима се извршавају, највиши ниво прилагодљивости који обезбеђује њихову доступност у случају катастрофе.
Годинама смо имали решења са синхроном функционалношћу репликације , али ова решења су била сложена за имплементацију и веома скупа. Обично је инсталација и иницијална конфигурација ових решења захтевала ангажовање професионалних услуга, одржавање је подразумевало ангажовање више добављача.
У овом блогу вам представљамо 3 решења, заснована на vSphere Metro Storage Cluster (vMSC), која су једноставна за примену и одржавање и имају цену о којој вреди размислити. Ова решења пружају бољу прилагодљивост ИТ инфраструктуре, него традиционална решења за опоравак катастрофа, али да би се постигла заштита на више нивоа требало би да имате трећу локацију која ће деловати као традиционална ДР локација. Такође , у случају отказивања ОС-а виртуелне машине или ransomware напада потребна је имати решење за креирање резервних копија података (backup). За креирање резервних копија препоручујемо решење које користи vSphere APIs for I/O Filtering (VAIO) као што је Cohesity који омогућава скоро нулти RPO и брз RTO.
vMSC – vSphere Metro Storage Cluster
vMSC је конфигурација која омогућава репликацију у оквиру storage кластера. У овој конфигурацији storage-и, којi су распоређени на обе локације, морају бити доступни са обе локације. Ове конфигурације се обично примењују у окружењима у којима су доступност и избегавање катасторфа кључни захтев. Сва уписивања на диск се изршавају синхроно, на обе локације, што осигурава доследност података без обзира на локацију са које се приступа. Ова архитектура захтева значајан проток, између две локације и врло ниску латенцију (до 10ms RTT).
У традиционалној синхроној репликацији постоји примарно секундарна релација између активног (примарног) LUN-а и огледала (секундарног) LUN-а. Да би приступили секундарном LUN-у, потребно је зауставити репликацију, и секундарни LUN представити хостовима са различитим LUN ид-ом.
У vMSC конфигурацији storage-и морају бити у могућности да читају и пишу на обе локације, записи на диску се синхроно уписују на обе локације да би се осигурало да су подаци увек усаглашени.
На основу начина на који хостови приступају storage-у , имамо два типа vMSC конфигурација:
- Uniform конфигурација приступа хостова, хостови са обе локације повезани су са свим storage нодовима на обе локације.
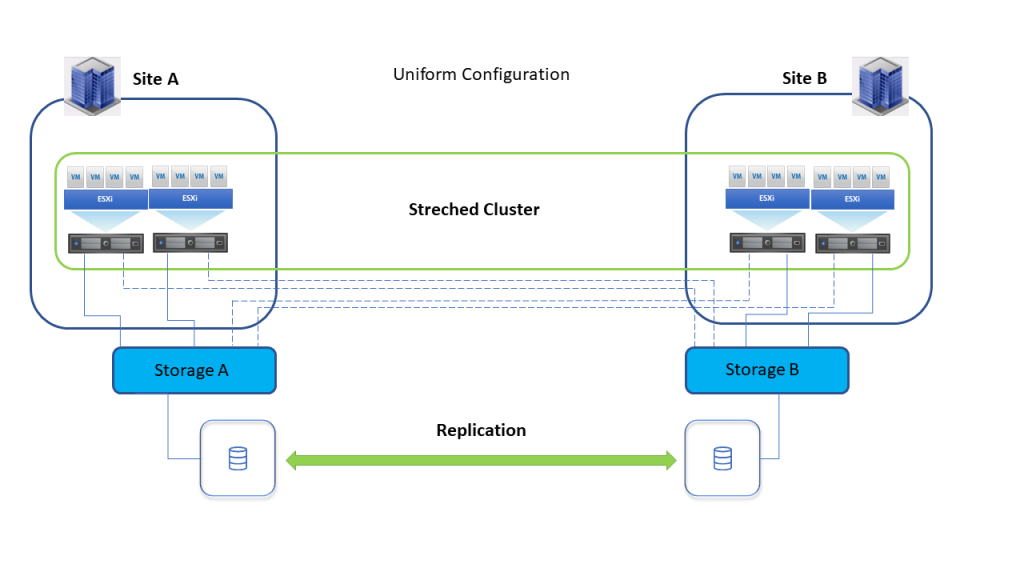
У случају отказа, недоступности, storage-а на локацији А, хостови са локације А ће приступити идентичном LUN-у кроз storage Б.
- Non-Uniform конфигурација приступа хостова, хостови са сваке локације су повезани само са storage нодовима унутар исте локације.
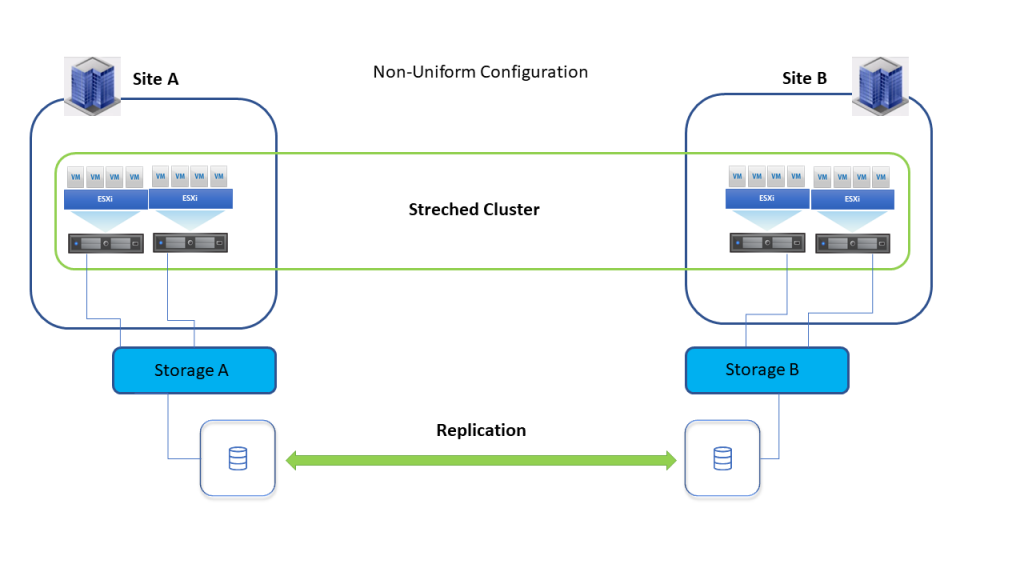
Са Non-Uniform конфигурацијом приступа хостова, у случају недоступности storage-а на локацији А, vSphere HA ће VM са локације А поново покренути на локацији Б.
Што се тиче лиценцирања са стране VMware не постоји минимални захтев за лиценцу, можете да креирате развучени (stretched) кластер са било којом лиценцом. Ако је потребно аутоматизовано балансирање радног оптерећења, из перспективе CPU-а или из перспективе storage-а, захтев је vSphere Enterprise Plus лиценца.
Pure Storage Active Cluster
Pure Storage® Purity ActiveCluster је потпуно симетрично активно / двосмерно репликационо решење које омогућава синхрону репликацију за RPO нула и аутоматски транспарентни failover за RTO нула. Функција ActiveCluster обезбеђује active/active storage у оквиру једне и на више физичких локација. Ове физичке локације могу бити у једном дата центру или потпуно различитим дата центрима повезаним везом са до 11ms RTT.
Нису потребни додатни хардвер ни лиценце. Синхрони записи репликације синхронизовани су између storage-а и заштићени у NVRAM-у на оба пре него што се упис потврди хосту. Транспарентни failover осигурава несметан прелаз између синхроно реплицираних storage-а са аутоматском ресинхронизацијом и опоравком.
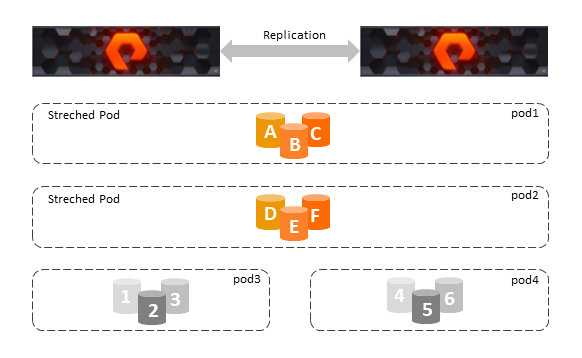
Purity ActiveCluster се састоји од три основне компоненте: Pure1 Mediator, active/active парови storage-a (верзија Purity 5.0.0 или већа) и развучени контејнери (Pod-ови)за складиштење података.
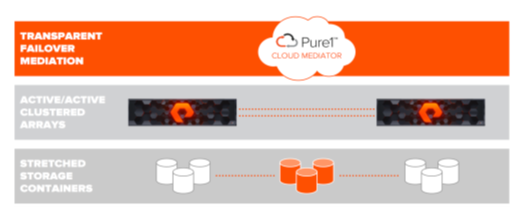
- ure1 Mediator је неопходна компонента која се користи за утврђивање који storage ће наставити да пружа услугу ако дође до отказа у окружењу. Медиатор мора бити смештен трећој локацији.. Сваки storage мора да има независну мрежну везу са медиатором, тако да појединачни одказ мреже не спречава оба да приступе медиатору. У случају да је потребан failover, веза са медиатором се остварује преко портова за управљање контролором. Препоручена конфигурација је да користите медиатор у облаку, који обезбеђује Pure, али ако storage-и немају приступ интернету доступна је и опција инсталације медиатора у локалној мрежи (OVA слика).
- ActiveCluster storage-у (волуменима) могу приступити хостови користећи uniform или non-uniform SAN топологију. Предност коришћења Pure Storage Purity ActiveCluster-а:
- Читање и писање је омогућено у волуменима ActiveCluster-а који се налазе у развученим контејнерима pod-овима
- Оптимизована путања се дефинише на основу везе између хоста и волумена помоћу унапред дефинисане опције.
- Pod је растегнути контејнер за складиштење који дефинише скуп објеката који су синхроно реплицирани заједно. Storage може да подржава више подова, под може да постоји само на једном или на два storage-а истовремено са синхроном репликацијом.
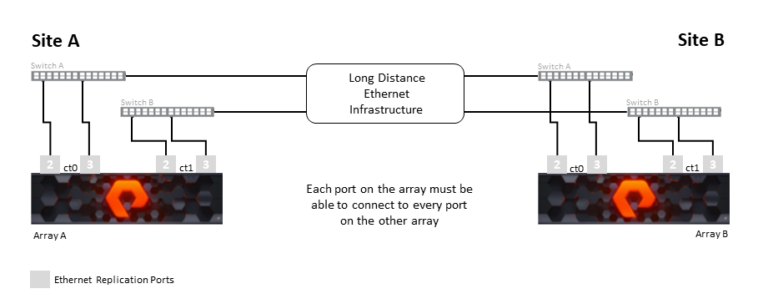
Мрежа репликације подржава повезивање storage-а линком кашњења до 11мм RTT. За репликацију су неопходна два ethernet порта по контролеру, повезана преко мрежне инфраструктуре. За редудантну конфигурацију коришћењем два мрежна уређаја на свакој локацији, сваки контролер мора имати везу са локалним мрежним уређајем и мрежна инфраструктура мора дозволити свим портовима за репликацију да међусобно комуницирају.
ActiveCluster је дизајниран да буде заиста active/active, где било који storage може да пружа I/O услуге за синхроно реплициране волумене. Uniform конфигурација приступа не захтева мануелне радње за потребе failover-а. У случају отказивања storage-а или отказивања везе са репликацијом која је узроковала заустављање I/O услуга, хостови доживљавају само губитак неких путања ка storage-у и настављају да користе друге путање до доступног storage-а. У non-uniform конфигурацији приступа VM које су изгубиле приступ storage-у, vSphere HA ће поново покренути на хостовима који су повезани са другим доступним storage-ом .
ActiveCluster укључује аутоматски начин за примену транспарентног failover-а, без интервенције корисника, користећи Pure1 Mediator за обезбеђивање кворум механизма. Транспарентни failover, између storage-а у ActiveCluster-у, је аутоматски.
У случају отказа репликационе везе, split brain, оба storage-а ће паузирати I/O, унутар стандардног временског ограничавања хостова, и допрети до медиатора да утврде који storage може да настави да служи I/O за сваки реплицирани pod. Када почне трка до медиатора ActiveCluster-а њен исход може бити непредвидив. То значи да у случају non-uniform хост конфигурације, недостатак предвиђања исхода медиаторске може довести до деструктивног поновног покретања апликације која ради на растегљеном волумену. ActiveCluster обезбеђује опцију преференце која омогућава администратору storage-а да утиче на исход трке. Опција за преференце даје жељеном storage-у, за сваки pod, додатних 6 секунди у трци до медиатора.
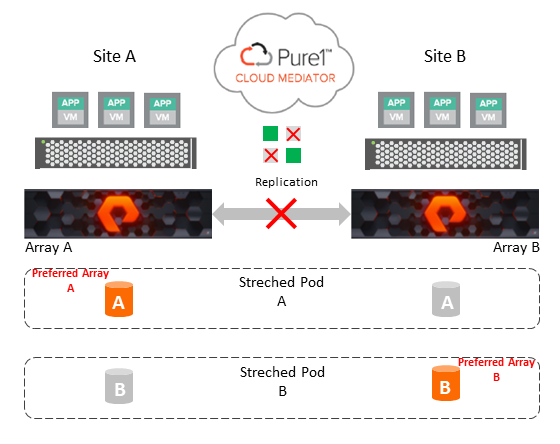
У non-uniform конфигурацији препоручује се постављање failover преференце као најбоља пракса. До поновног покретања VM долази само у случајевима када је један storage ван мреже или када се цела локација изгуби.
Са Purity 5.3 верзијом ActiveCluster уведен је pulling механизам медиатора. Ова функција омогућава да се оба storage-а сложе ко ће бити победник трке, за сваки развичени pod, ако оба да се не могу да стигну до медиатора. Преференце пода се користе за одређивање победника (уколико је подешена опција). Ако није подешена жељена преференце отказивање пода, победник ће бити аутоматски изабран. У следећој табели доступност растегнутих волумена pod-а даје се на основу отказивања различитих компоненти решења.
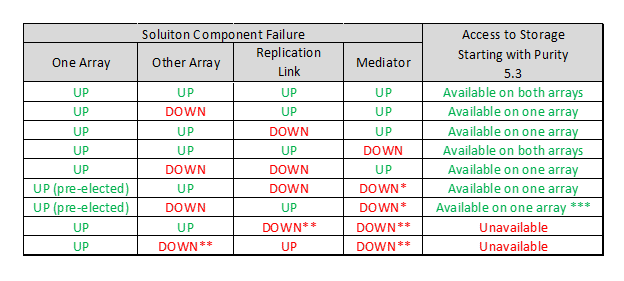
* Предизборни завршен пре отказивања друге компоненте.
** Симултани кварови компоненти.
***Претпоставља да „други “ није унапред изабран. Ако предизабрани storage откаже волумени подова нису доступни.
Ресинхронизација и опоравак су аутоматски, интервенција администратора storage-а није потребна за опоравак и резинхронизовање репликације активног кластера.
NetApp SnapMirror business continuity (SM-BC)
ONTAP 9.8 уводи SnapMirror Business Continuity (SM-BC), што омогућава да се оптерећења истовремено служе на оба кластера. SM-BC је непрекидно доступно решење за складиштење, доступно за NetApp ONTAP® који ради на NetApp AFF или NetApp All SAN Array (ASA) storage системима. SM-BC подржава само HA кластере са два storage система (AFF или ASA), није потребан додатни хардвер.
У поређењу са SnapMirror Synchronuos (SM-S), који захтева мануелни failover или коришћење менаџмент DR решења, SM-BC омогућава аутоматизован failover без икакве мануелне интервенције. SM-BC задржава LUN идентитет између две копије, тако да их апликације виде као дељени LUN. Грануларност апликације је омогућена помоћу consistency групa, са аутоматским failover-ом на секундарну копију без губитка података. Поред континуитета пословања, SM-BC омогућава додатне случајеве коришћења као што је коришћење друге копије за тестирање и развој. ONTAP медиатор је потребан на трећој локацији. SM-BC не захтева додатне лиценце све док кластер има Data Protection или Premium Bundle лиценце.
SM-BC пружа следеће предности:
- Грануларност апликације за континуитет пословањаr business continuity
- Аутоматизован failover са могућношћу тестирања failover-а за сваку апликацију.
- LUN идентитет остаје исти, тако да их апликација види као дељени виртуелни уређај.
- Могућност да се секундарни са флексибилношћу поново користите да бисте креирали тренутне клонове за коришћење апликација у сврхе тестирања и развоја, UAT -а или извештавања, без утицаја на перформансе апликације или доступност.
- Поједностављено управљање апликацијама помоћу consistency група да би се одржала зависна доследност налога за писање.
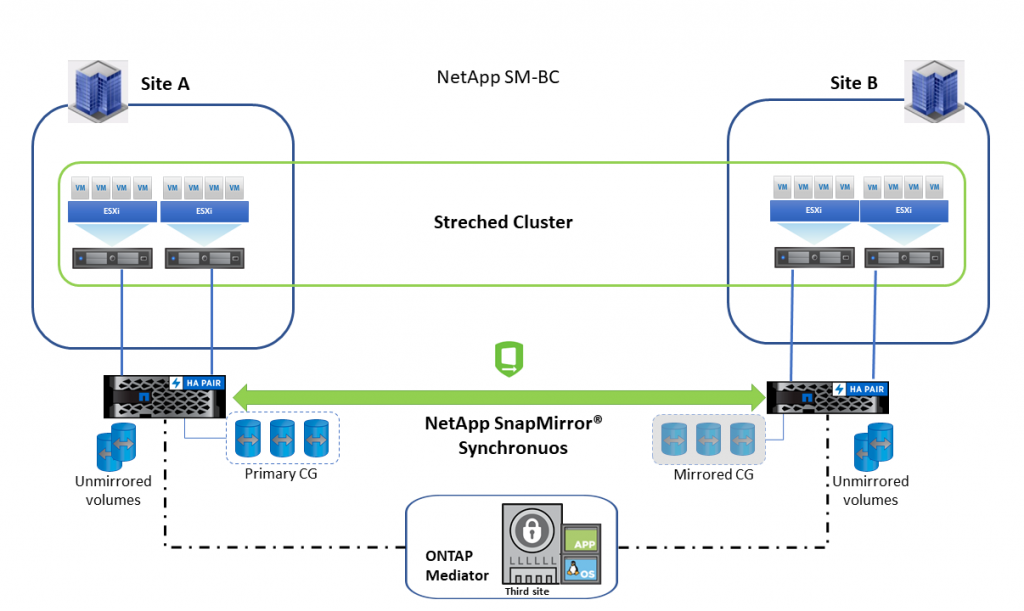
SM-BC архитектура пружа активна радна оптерећења на оба кластера, где се примарна радна оптерећења могу сервирати истовремено из оба кластера. Однос заштите података ради заштите континуитета пословања се креира између система изворног складишта и одредишног система складиштења. При нормалним операцијама, пословна апликација пише у примарној consistency групи, која синхроно реплицира овај I/O у mirror consistency групу. Иако постоје две засебне копије у односу на заштиту података, зато што SM-BC задржава исти LUN идентитет, хост види ово као дељени виртуални уређај са више путања док се у исто време пише само једна LUN копија. Када дође до грешке и примарни storage систем буде ван мреже, ONTAP медиатор открива овај отказ и омогућава транспарентни прелаз на mirror consistency групу. Овај процес резултира failover без потребе за ручном интервенцијом или извршавањем скрипти која је претходно била потребна ову намену.
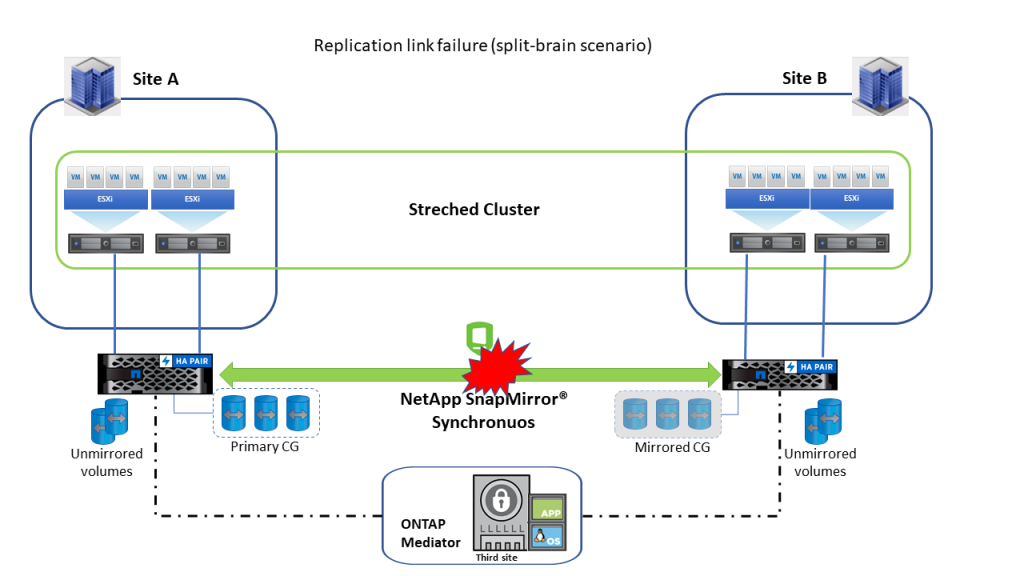
У случају отказа репликационог везе, NetApp® ONTAP® медиатор открива овај отказ. Примарни LUN наставља да служи I/O хостовима а сви путање ка секундарном storage кластеру пријављују illegal request/LU not found.
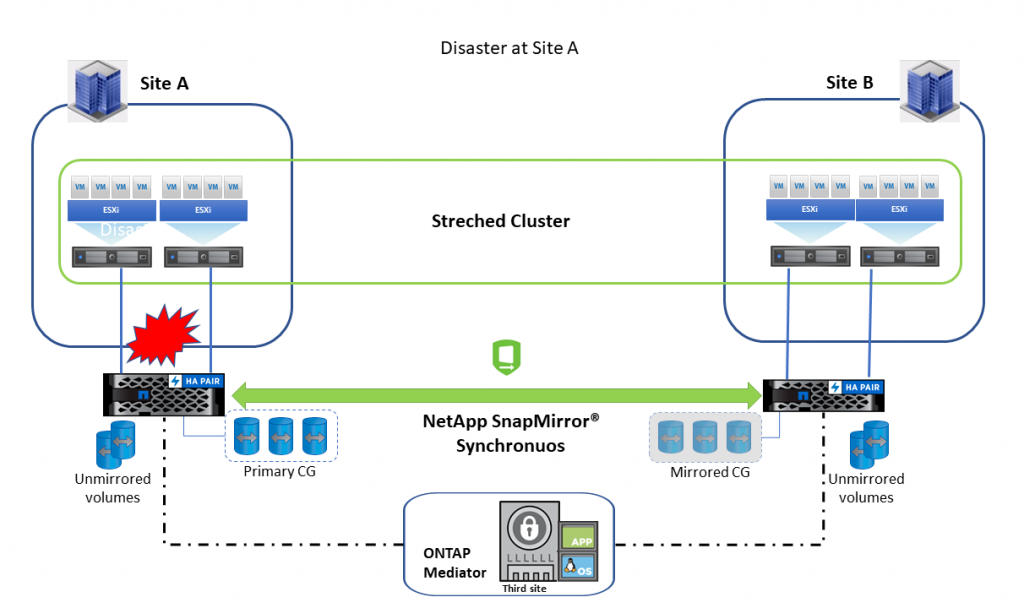
У случају катастрофе на локацији А, медиатор открива отказ , обавештава секундарни сајт и секундарни LUN наставља да служи I/O хостовима. Када се локација А врати на мрежу медиатор ће успоставити релацију у супротном смеру, доделите улогу секундарног волумена локацији А. Након релације достизања стања синхронизације може се извршити планиран failover да би се вратиле нормалне операције.
У случају катастрофе на локацији Б, примарни LUN наставља да серверира I/O хостовима.
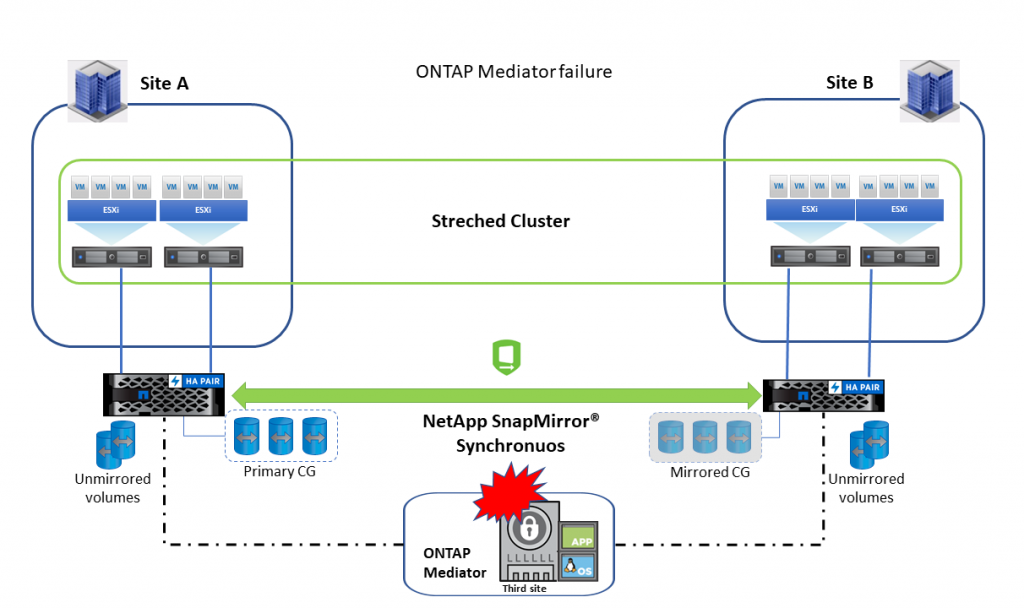
У случају отказивања Програма NetApp® ONTAP® медиатора (виртуелна машина), примарни LUN наставља са пружањем I/O хостовима и релација наставља да се синхронизује. Пошто ONTAP медиатор није доступан, AUFO (automatic unplanned) или PFO (planned) failover нису могући.
vSAN Streched Cluster
У поређењу са претходним решењима, која се заснивају на физичком storage-има, vSAN Stretched Cluster се заснива на VMware vSAN софтверски дефинисаној storage архитектури. vSAN је storage решење које ради на стандардном x86 хардверу. Интегрисан је у језгро vSphere и потпуно је интегрисан са другим vSphere функционалностима као што су HA, DRS, vMotion. vSAN datastore се састоји од свих локалних дискова који су агрегирани у једно складиште података које деле сви хостови у кластеру.
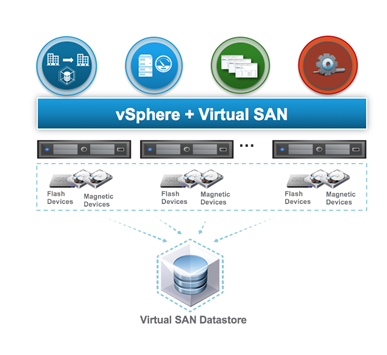
Почетна инсталација и одржавање су много лакши, у поређењу са претходним решењима, с обзиром да се конфигурација изводи из vSphere клијента. Због начина на који функционише vSAN, нема потребе за конфигурисањем репликације складишта података. Инсталација vSAN Stretched Cluster-а се у потпуности обавља из vSphere чаробњака. Минимум за инсталцију је 2+ 1 witness и максимално 40 ESXi хостова + 1 witness (vSAN 7 U2). На трећој локацији се поставља witness (физички или виртуелни).
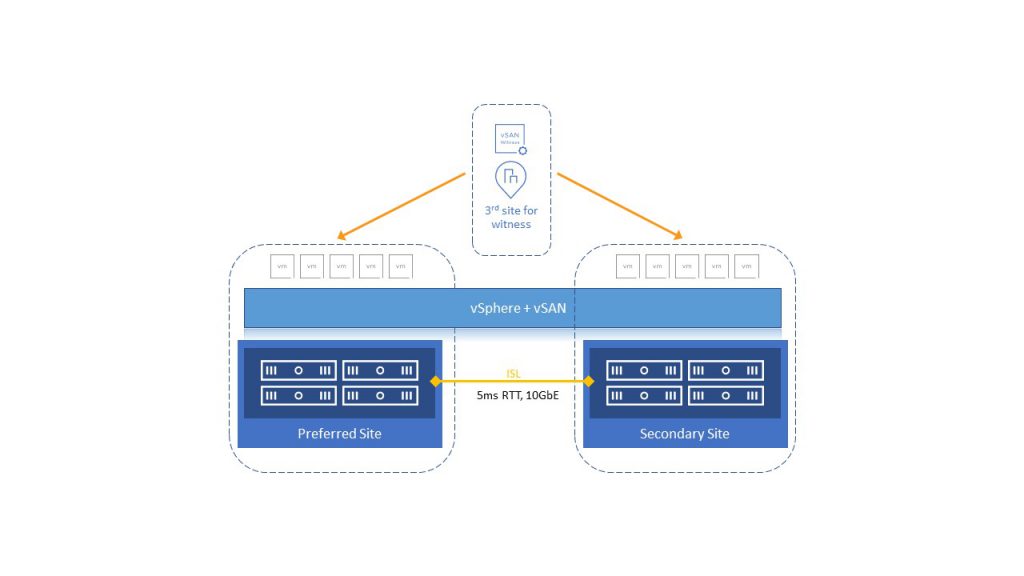
Предности конфигурације vSAN Stretched Cluster-а су:
- Избегавање катастрофа и планиран failover (одржавање)
- Active-Active датацентар
- Лако управља са једним vSphere vCenter сервером
- Доступност високог нивоа сајта за одржавање континуитета пословања
- Аутоматски опоравак у случају да једна од локација није доступна
- Једноставна и бржа имплементација, у поређењу са растегнутим кластером користећи традиционалне системе складиштења
vSAN Stretched Cluster је HCI решење које се протеже између три удаљене локације или fault domena (FD), то укључује preferred, secondary и witness. Током почетне конфигурације потребно је одлучити која ће локација бити preferred, а ово је важно ако имамо split brain сценарио (прекид ISL линка). У овом сценарију, чак и ако secondary локација здрава, vSphere HA ће поново покренути VM са secondary на preferred локацију.
У vSAN-у користимо Storage policies за дефинисање захтева за складиштење виртуелних машина за перформансе и доступност. Поред подразумеваних Storage policy између активних локација које су Raid1, са vSAN 6.6 имамо и додатну опцију за локалну заштиту и афинитет локације. Локална заштита или FTT, на локацији се односи на број отказивања (0 до 3) и може бити raid1 или raid5/6. Уз Site Affinity Policy, можемо да дефинишемо за које објекте заштита на локацијама није жељена.
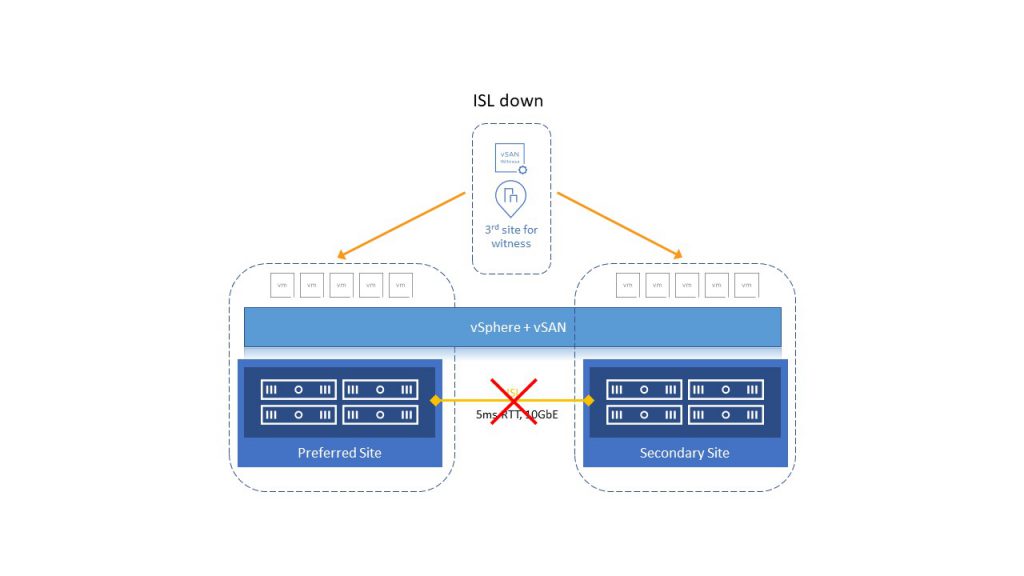
У случају да кластер изгуби комуникацију између локација (прекид ISL), кворум ће бити успостављен између preferred локације и witness. vSphere HA ће поново покренути VM са секундарне локације на preferred локацију. Зато је важно утврдити, у иницијалној конфигурацији, која ће од две локације бити preferred.
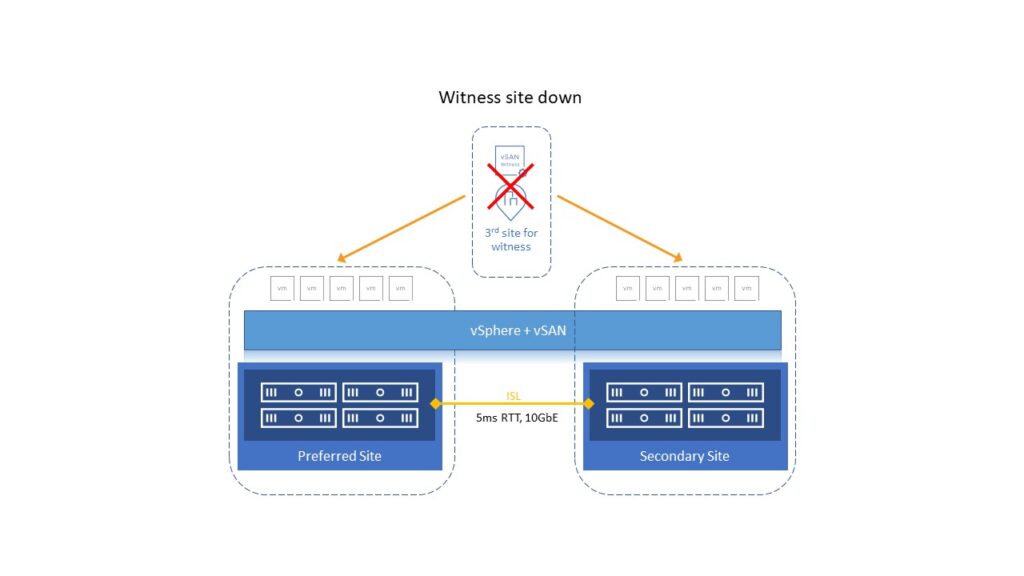
Ако је witness локација недоступна (или мрежно изолована), све VM настављају да се извршавају на својим локацијама.
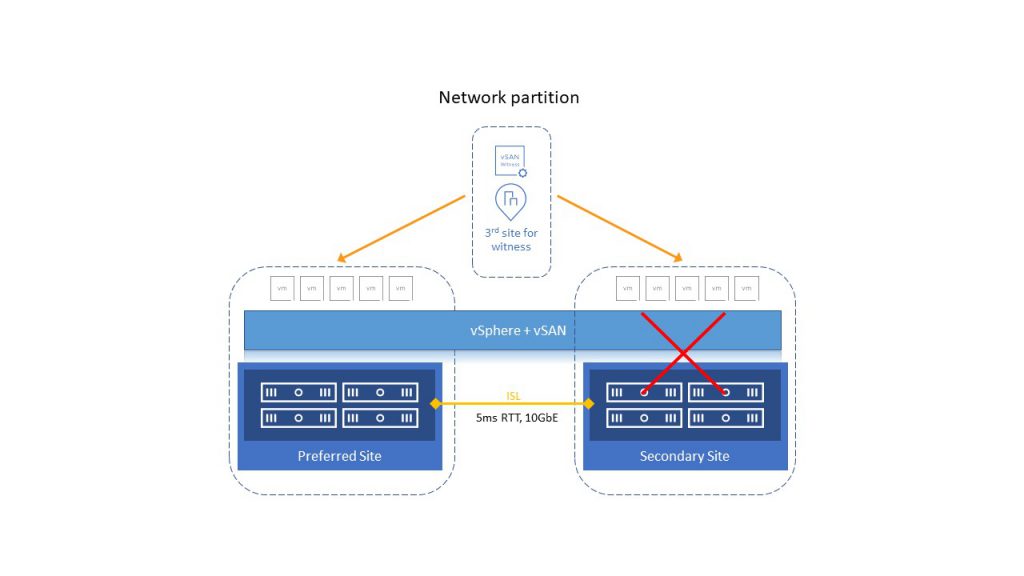
Ако једна од локација не ради или постане мрежно изолована, кворум ће бити успостављен између преживелог сајта и witness локације. Све VM из изгубљене или изоловане локације ће поново покренути vSphere HA на другој локацији.
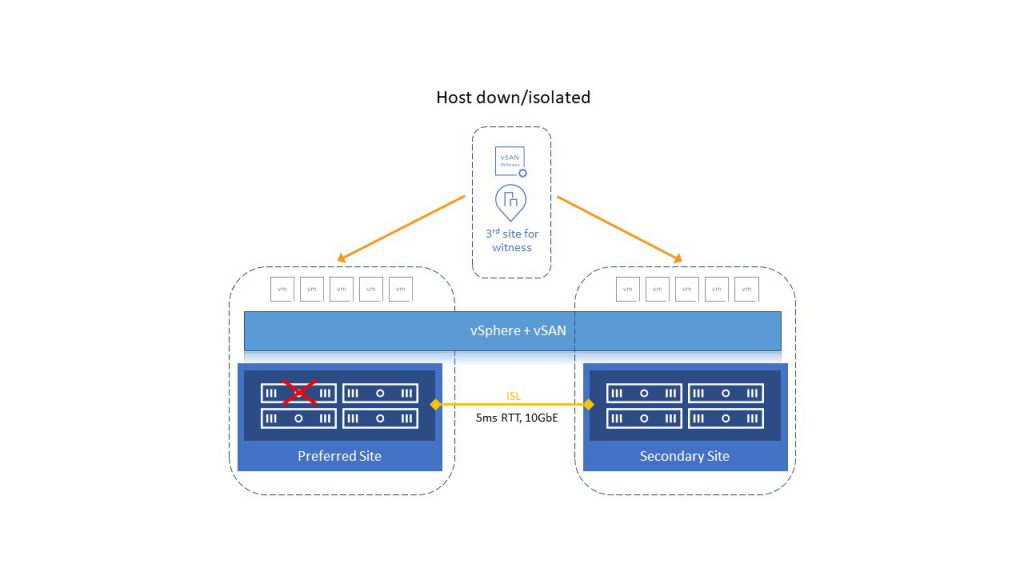
У случају да кластер изгуби једног од хостова, HA ће рестаурирати те VM на другом хосту. Ако се хост не опорави за 60 минута све компоненте које су биле на том хосту биће аутоматски креиране на једном од преосталих хостова.
Закључак
Применом vMSC добијамо исте предности које пружа кластер високе доступности на једној локацији али у оквиру два дата центра који су географски раздвојени. Кластер се налази на две локације и са њим се управља једним vCenter сервером. Виртуелне машине у VMSC-у можемо мигрира између локација са vSphere vMotion и vSphere Storage vMotion. Растојање између центара података је ограничено (захтев RTT кашњења).
Избегавање катастрофа значајно смањује вероватноће да ће доћи до катастрофе и пружа бољу прилагодљивост него традиционални опоравак у катастрофи. Међутим , да би се постигла заштита на више нивоа, трећа локација је потребна као традиционална др.